

by: TweakTown
TSMC begins work on 'world's most advanced' chip fab, costs $48.5 billion for 1.4nm production











by: Fox News












by: The Irish News
Studio Ulster and Dell Technologies Join Forces to Revolutionize Virtual-Production

by: Seeking Alpha
Wave Life Sciences Q3 2025 Earnings Call: 14% Revenue Growth and Strong Operating Margins








 Earnings Transcript | The Motley Fool")

")










The Role of Data Science in Bottleneck Calculator Optimization
 Impacts
Impacts

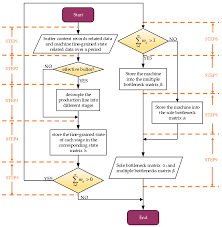

The Role of Data Science in Bottleneck Calculator Optimization
In today’s high‑velocity digital environment, organizations that rely on predictive analytics and optimization algorithms must continually refine the tools that surface the most critical constraints in their systems. A bottleneck calculator—an analytical engine that pinpoints the single or set of resources limiting throughput—is one such tool. The article on TechBullion, “The Role of Data Science in Bottleneck Calculator Optimization,” explores how data science methods transform the accuracy, scalability, and usability of bottleneck calculators, turning them from static lookup tables into dynamic, self‑learning systems.
1. From Rule‑Based Models to Data‑Driven Insight
Historically, bottleneck calculators were built on deterministic rules or handcrafted heuristics. Engineers would specify thresholds and constraints, then let the system flag the resource that fell below its target. While effective for simple systems, this approach quickly broke down in complex, multi‑layered architectures. The TechBullion piece highlights how data science replaces hard‑coded rules with probabilistic models that learn from historical performance data.
The core idea is to treat bottleneck identification as a supervised learning problem. By labeling past system states with the known bottleneck (or lack thereof), a classification model can predict the bottleneck in new, unseen scenarios. Algorithms such as Random Forests, Gradient Boosting Machines, or even neural networks can be trained on features like CPU usage, memory consumption, queue lengths, and network latency. The resulting model not only flags the bottleneck but also estimates the severity and potential impact on overall throughput.
2. Feature Engineering: The Bridge Between Raw Data and Prediction
A critical part of the transformation is feature engineering. The article notes that raw telemetry streams—such as those from Prometheus, Grafana, or custom instrumentation—must be aggregated into meaningful metrics. Time‑series decomposition, moving averages, variance calculations, and lag features help capture both short‑term spikes and long‑term trends.
Additionally, contextual features—like scheduled maintenance windows, batch job start times, or user load patterns—provide a richer picture. For instance, a CPU bottleneck that appears only during a nightly data ingestion batch is markedly different from one that occurs during peak user traffic. By incorporating such variables, models gain discriminative power and avoid false positives.
3. Real‑Time Inference and Edge Deployment
The TechBullion article emphasizes the importance of low‑latency inference for bottleneck calculators that need to operate in real‑time. Deploying models as microservices on Kubernetes or as serverless functions enables horizontal scaling. Lightweight model formats (e.g., ONNX, TensorRT) and quantized inference engines reduce CPU and memory footprints, allowing the calculator to run close to the data source—often referred to as “edge deployment.”
The article cites an example where a telecom provider deployed a bottleneck calculator on its network edge. By running inference on local routers, the system could detect a packet loss bottleneck within milliseconds, allowing dynamic rerouting before the issue impacted end users.
4. Continuous Learning and Model Drift Mitigation
One challenge with data‑driven bottleneck calculators is concept drift: the underlying relationships between features and bottlenecks change over time. The article discusses strategies to keep models current, including:
- Scheduled Retraining: Periodic re‑training on the latest data (e.g., nightly) to capture new patterns.
- Online Learning: Incremental updates that absorb new observations without full retraining.
- Drift Detection: Statistical tests (e.g., Kolmogorov–Smirnov, population stability index) that flag significant changes in feature distributions or model predictions.
By coupling these techniques with a robust CI/CD pipeline for model deployment, organizations can maintain high precision and recall in bottleneck detection.
5. Human‑In‑The‑Loop and Explainability
Despite advances in automation, the article reminds readers that bottleneck calculators ultimately support human decision‑makers. Explainable AI (XAI) techniques—such as SHAP values, LIME explanations, or decision trees—can illuminate why a particular resource was flagged. This transparency helps engineers trust the system, diagnose root causes, and prioritize remediation actions.
The TechBullion piece presents a case study from a manufacturing plant where the bottleneck calculator flagged a conveyor belt’s motor as the limiting resource. The SHAP explanation revealed that motor temperature correlated strongly with throughput reduction, prompting an early maintenance schedule that prevented a costly shutdown.
6. Integration with Orchestration and Automation Tools
Finally, the article explores how bottleneck calculators can be integrated into broader observability and automation stacks. By exposing predictions via APIs, the calculator can trigger automated responses—such as scaling cloud instances, re‑routing traffic, or re‑balancing workloads—without human intervention. The article references integration patterns with popular tools like Terraform, Ansible, and cloud‑native services (e.g., AWS Step Functions, Azure Logic Apps).
7. Future Directions: Meta‑Learning and Federated Analytics
Looking ahead, the TechBullion article touches on emerging research in meta‑learning—where models learn how to adapt quickly to new bottleneck types—and federated analytics, which aggregates insights from distributed edge devices while preserving privacy. These advancements promise even more agile and resilient bottleneck calculators capable of operating across heterogeneous environments.
Conclusion
The transition from rule‑based to data‑driven bottleneck calculators marks a pivotal shift in how organizations approach system optimization. By leveraging supervised learning, sophisticated feature engineering, real‑time inference, continuous learning, explainability, and orchestration integration, data science elevates bottleneck detection from a manual diagnostic task to an automated, predictive capability. As the complexity of distributed systems grows, these data‑science‑powered tools will become essential for maintaining performance, reducing downtime, and delivering a seamless experience to end users.
Read the Full Impacts Article at:
https://techbullion.com/the-role-of-data-science-in-bottleneck-calculator-optimization/
Like: 👍
on: Sat, Aug 23rd 2025
by: deseret
A newspaper that has kept up with the latest technologies through the years

on: Thu, Nov 06th 2025
by: Searchenginejournal.com
Deploying Agentic AI For SEO: A Playbook For Technology Leaders

on: Mon, Oct 27th 2025
by: Forbes
How Today's Technology Can Eliminate CX Friction: Tech Pros' Tips

on: Fri, Oct 10th 2025
by: Searchenginejournal.com

on: Mon, Sep 29th 2025
by: Nigerian Tribune

on: Sat, Jul 26th 2025
by: The Cool Down
AI Startups Revolutionizing Healthcare with Advanced Diagnostics

on: Tue, Nov 04th 2025
by: Impacts
Advanced Capsule Manufacturing: Where Technology Meets Precision

on: Wed, Oct 29th 2025
by: The Motley Fool

on: Wed, Oct 22nd 2025
by: Toronto Star
 to Present at the AI & Technology Virtual Investor Conference October 28th")
on: Tue, Oct 21st 2025
by: Impacts
Exploring the Advancements in Chain Manufacturing Technologies

on: Tue, Oct 21st 2025
by: The Jerusalem Post Blogs
Odysight.ai(R) Reports Successful Technology Demonstration | The Jerusalem Post
 Reports Successful Technology Demonstration | The Jerusalem Post")
on: Tue, Oct 14th 2025
by: Impacts
